Fehlerbeschreibung
bitte beschreibe den aufgetretenen Fehler so ausführlich wie möglich
Was ist passiert?:
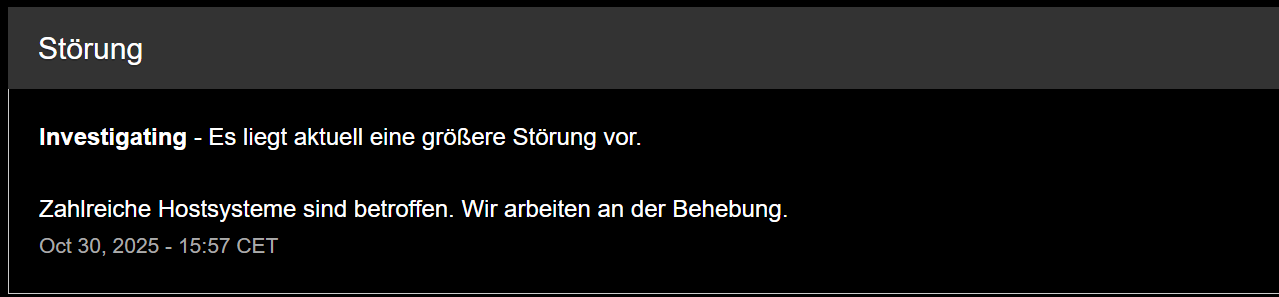
Wiki, Phorge ab ca. 15:40 nicht erreichbar!
Weitere Informationen
Systemdetails (Name/Version des Browsers, Softwareversion der Andwenudng)
Zusatzinformation
(Screenshots, etc.):